A major upgrade to Megaparsec: more speed, more power
Published on July 6, 2017
It looks like comparing Haskell’s performance with C (even just FFI) causes too much disturbance in the force, so this time I’ll be comparing Haskell with Haskell, namely Megaparsec 6 (still in making) with the gold standard of fast parsing in the Haskell world—Attoparsec.
The post is about a modification to Megaparsec extending its Stream type
class to achieve four goals:
-
Allow to return more natural types from things like
string. If you parseTextstream, you should getTextfrom there, with minimal repacking/overhead. (Megaparsec 5 returnsString ~ [Char]for any stream of tokensChar.) -
Reduce allocations and increase speed. Consuming input token by token and repacking them into
Stringfor example is not most efficient way to parse a row of tokens. Surely we can do better. -
Add more combinators like
takeWhile, which should return “chunks” of input stream with correct type (e.g.ByteStringif we parseByteStringstream). This is to match what Attoparsec can do. -
Make code simpler by moving the complex position-updating logic that we keep for custom streams of tokens into the methods of the
Streamtype class. This way if you have a custom stream of tokens, you’ll have to write the correct position updating code. At the same time, default streams (String,Text,ByteString) will enjoy simplified, faster processing.
Benchmarks
We’re going to need some benchmarks. I have made the repo with the code I used for comparison public, it can be found here: https://github.com/mrkkrp/parsers-bench.
It contains 3 pairs of parsers:
- CSV parser (original code)
-
JSON parser (stolen from Attoparsec’s
Aeson.hsbenchmark with simplifications) - Log parser (stolen from School of Haskell tutorial)
I do not want to focus on microbenchmarks, instead I want to compare “common place”, average parsing code people usually write with the libraries (fortunately the code written using Attoparsec is easily convertable to Megaparsec). To make the comparison fair, I also do not use complex monadic stacks with Megaparsec, as it would surely make it slower (with Attoparsec you just can’t do that after all).
Running the benchmark with Megaparsec before any Stream-related
optimizations gives us the starting point:
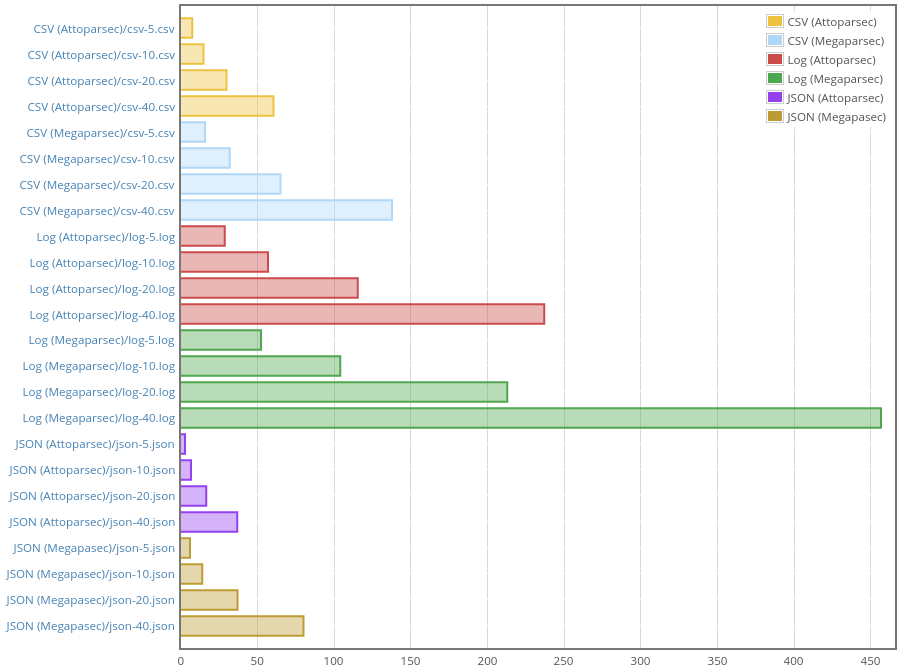
Honestly, this is better than I expected. Average Megaparsec parser is just twice as slow as average Attoparsec parser. Now what is really interesting is how close we can get to performance of the venerable library without compromising on flexibility and quality of error messages.
Extending Stream and adding new primitives
In this section I’m going to explain how the Stream type class has been
extended (or rather re-written) to allow for a more efficient (and simpler)
tokens implementation and addition of completely new primitive
combinators. After that we’ll see if it helps with performance.
tokens
Let’s start with tokens, which is a familiar primitive: string and
string' are implemented in terms of it. It allows to match a fixed chunk
of stream (that is, several tokens in a row). It also backtracks
automatically in modern versions of Megaparsec, which makes it easier to
just slice and compare a “chunk” of stream directly and efficiently.
There are several possible implementations that would require different
methods to be added to Stream. I went with extracting a chunk of fixed
length equal to the length of the chunk we want to match against, then
comparing it using user-supplied function to figure out if what we’ve
fetched is a match.
The implementation currently looks like this:
pTokens :: forall e s m. Stream s
=> (Tokens s -> Tokens s -> Bool)
-> Tokens s
-> ParsecT e s m (Tokens s)
pTokens f tts = ParsecT $ \s@(State input (pos:|z) tp w) cok _ _ eerr ->
let pxy = Proxy :: Proxy s
unexpect pos' u =
let us = pure u
ps = (E.singleton . Tokens . NE.fromList . chunkToTokens pxy) tts
in TrivialError pos' us ps
len = chunkLength pxy tts
in case takeN_ len input of
Nothing ->
eerr (unexpect (pos:|z) EndOfInput) s
Just (tts', input') ->
if f tts tts'
then let !npos = advanceN pxy w pos tts'
in cok tts' (State input' (npos:|z) (tp + len) w) mempty
else let !apos = positionAtN pxy pos tts'
ps = (Tokens . NE.fromList . chunkToTokens pxy) tts'
in eerr (unexpect (apos:|z) ps) (State input (apos:|z) tp w)
If it doesn’t make much sense to you, it’s OK. The point here is that we
need this takeN_ primitive to grab N tokens from input stream:
-- | Type class for inputs that can be consumed by the library.
class (Ord (Token s), Ord (Tokens s)) => Stream s where
-- | Type of token in the stream.
type Token s :: *
-- | Type of “chunk” of the stream.
type Tokens s :: *
-- | Extract a single token form the stream. Return 'Nothing' if the
-- stream is empty.
take1_ :: s -> Maybe (Token s, s)
-- | @'takeN_' n s@ should try to extract a chunk of length @n@, or if the
-- stream is too short, the rest of the stream. Valid implementation
-- should follow the rules:
--
-- * If the requested length @n@ is 0 (or less), 'Nothing' should
-- never be returned, instead @'Just' (\"\", s)@ should be returned,
-- where @\"\"@ stands for the empty chunk, and @s@ is the original
-- stream (second argument).
-- * If the requested length is greater than 0 and the stream is
-- empty, 'Nothing' should be returned indicating end of input.
-- * In other cases, take chunk of length @n@ (or shorter if the
-- stream is not long enough) from the input stream and return the
-- chunk along with the rest of the stream.
takeN_ :: Int -> s -> Maybe (Tokens s, s)
As you can see, takeN_ returns Tokens s thing, where Tokens is a new
associated type of the Stream type class. It’s the same as stream type for
built-in streams (String, strict and lazy Text and ByteString), but it
may be desirable to have something that differs from the stream type s
when working with custom streams.
take1_ is our old workhorse uncons under different name—truly the most
common operation in parsing (basis of the token primitive), but we’ll talk
more about that later when analyzing performance.
takeN_ is in foundation of tokens for another reason as well—we’d like
to keep the number of Stream‘s methods minimal, and takeN_ can be used
to implement many useful combinators such as match:
-- | Return both the result of a parse and the list of tokens that were
-- consumed during parsing. This relies on the change of the
-- 'stateTokensProcessed' value to evaluate how many tokens were consumed.
-- If you mess with it manually in the argument parser, prepare for
-- troubles.
--
-- @since 5.3.0
match :: MonadParsec e s m => m a -> m (Tokens s, a)
match p = do
tp <- getTokensProcessed
s <- getInput
r <- p
tp' <- getTokensProcessed
-- NOTE The 'fromJust' call here should never fail because if the stream
-- is empty before 'p' (the only case when 'takeN_' can return 'Nothing'
-- as per its invariants), (tp' - tp) won't be greater than 0, and in that
-- case 'Just' is guaranteed to be returned as per another invariant of
-- 'takeN_'.
return ((fst . fromJust) (takeN_ (tp' - tp) s), r)
If you look carefully at the definition of pTokens, you’ll notice more
methods of Stream: positionAtN, advanceN, and chunkLength.
-- | Type class for inputs that can be consumed by the library.
class (Ord (Token s), Ord (Tokens s)) => Stream s where
-- …
-- | Set source position __at__ given token. By default, the given
-- 'SourcePos' (second argument) is just returned without looking at the
-- token. This method is important when your stream is a collection of
-- tokens where every token knows where it begins in the original input.
positionAt1
:: Proxy s -- ^ 'Proxy' clarifying the type of stream
-> SourcePos -- ^ Current position
-> Token s -- ^ Current token
-> SourcePos -- ^ Position of the token
positionAt1 Proxy = defaultPositionAt
-- | The same as 'positionAt1', but for chunks of the stream. The function
-- should return the position where the entire chunk begins. Again, by
-- default the second argument is returned without modifications and the
-- chunk is not looked at.
positionAtN
:: Proxy s -- ^ 'Proxy' clarifying the type of stream
-> SourcePos -- ^ Current position
-> Tokens s -- ^ Current chunk
-> SourcePos -- ^ Position of the chunk
positionAtN Proxy = defaultPositionAt
-- | Advance position given a single token. The returned position is the
-- position right after the token, or position where the token ends.
advance1
:: Proxy s -- ^ 'Proxy' clarifying the type of stream
-> Pos -- ^ Tab width
-> SourcePos -- ^ Current position
-> Token s -- ^ Current token
-> SourcePos -- ^ Advanced position
-- | Advance position given a chunk of stream. The returned position is
-- the position right after the chunk, or position where the chunk ends.
advanceN
:: Proxy s -- ^ 'Proxy' clarifying the type of stream
-> Pos -- ^ Tab width
-> SourcePos -- ^ Current position
-> Tokens s -- ^ Current token
-> SourcePos -- ^ Advanced position
-- | Return length of a chunk of the stream.
chunkLength :: Proxy s -> Tokens s -> Int
positionAt1 and positionAtN set position at single token and given chunk
of stream respectively. For all the built-in streams it’s enough to just
return the given source position:
defaultPositionAt :: SourcePos -> a -> SourcePos
defaultPositionAt pos _ = pos
Because in input like aaab, if we have matched all as, we are
automatically at b‘s position—that’s it. The methods are more useful for
streams of tokens where every token contains its position in original input,
for example:
data Span = Span
{ spanStart :: SourcePos
, spanEnd :: SourcePos
, spanBody :: NonEmpty Char
} deriving (Eq, Ord, Show)
instance Stream [Span] where
type Token [Span] = Span
type Tokens [Span] = [Span]
positionAt1 Proxy _ (Span start _ _) = start
positionAtN Proxy pos [] = pos
positionAtN Proxy _ (Span start _ _:_) = start
advance1 Proxy _ _ (Span _ end _) = end
advanceN Proxy _ pos [] = pos
advanceN Proxy _ _ ts =
let Span _ end _ = last ts in end
chunkLength Proxy = length
take1_ [] = Nothing
take1_ (t:ts) = Just (t, ts)
takeN_ n s
| n <= 0 = Just ([], s)
| null s = Nothing
| otherwise = Just (splitAt n s)
advance1 and advanceN position stream right after parsed token or chunk.
For built-in streams advanceN is just defined via advance1 and a strict
left fold over given chunk.
chunkLength should be obvious—without it we wouldn’t be able to keep track
of the total number of processed tokens.
Isomorphism between [Token s] and Tokens s
Let’s see more methods of Stream:
-- | Type class for inputs that can be consumed by the library.
class (Ord (Token s), Ord (Tokens s)) => Stream s where
-- …
-- | The first method that establishes isomorphism between list of tokens
-- and chunk of the stream. Valid implementation should satisfy:
--
-- > chunkToTokens pxy (tokensToChunk pxy ts) == ts
tokensToChunk :: Proxy s -> [Token s] -> Tokens s
-- | The second method that establishes isomorphism between list of tokens
-- and chunk of the stream. Valid implementation should satisfy:
--
-- > tokensToChunk pxy (chunkToTokens pxy chunk) == chunk
chunkToTokens :: Proxy s -> Tokens s -> [Token s]
chunkToTokens is primarily necessary to report chunks of input in parse
errors. There will be a different blog post about changes related to parse
errors, but it suffices to say that unexpected and expected tokens are
ErrorItems, defined like this:
data ErrorItem t
= Tokens (NonEmpty t) -- ^ Non-empty stream of tokens
| Label (NonEmpty Char) -- ^ Label (cannot be empty)
| EndOfInput -- ^ End of input
This removes weird errors like unexpected "" or expecting "" and merges
one token/many tokens case into the single constructor Tokens (NonEmpty t)
simplifying error reporting and making it more uniform (you can’t get
different renderings of essentially the same thing like "a" and 'a', if
there is one token, it’s always formatted 'a', if there are more tokens,
string-like syntax is used: "aa").
To get NonEmpty t, we need to get [Token s] (remember t ~ Token s), so
that’s what chunkToTokens is for. (Don’t worry, because of the
requirements we state for takeN_, NE.fromList never blows up in
pTokens).
There are reasons to request also tokensToChunk—that is, mapping in the
opposite direction. Here is a motivating example:
-- | Parse a carriage return character followed by a newline character.
-- Return the sequence of characters parsed.
crlf :: forall e s m. (MonadParsec e s m, Token s ~ Char) => m (Tokens s)
crlf = string (tokensToChunk (Proxy :: Proxy s) "\r\n")
-- reminder:
string :: MonadParsec e s m => Tokens s -> m (Tokens s)
string = tokens (==)
string takes Tokens s, but if we add constraint like Tokens s ~ Text,
crlf will be useful with only one type of input stream. We can just
request that Token s ~ Char if we can convert list of tokens [Char] to
the chunk type. This way, the same crlf function works out-of-the-box with
String, strict and lazy Text, and any other Stream instance with
Token s ~ Char that user may add. (We could go with IsString (Tokens s),
in this particular case but it’s a less-general solution because tokens may
have nothing to do with characters and IsString may make no sense for
Tokens s type).
So for instances of Stream we request that list of tokens [Token s] and
Tokens s are isomorphic with tokensToChunk and chunkToTokens acting as
a way to switch representations:
chunkToTokens pxy (tokensToChunk pxy ts) == ts
tokensToChunk pxy (chunkToTokens pxy chunk) == chunk
One special case is lifting single token to the chunk type, like in this
eol parser:
-- | Parse a CRLF (see 'crlf') or LF (see 'newline') end of line. Return the
-- sequence of characters parsed.
eol :: forall e s m. (MonadParsec e s m, Token s ~ Char) => m (Tokens s)
eol = (tokenToChunk (Proxy :: Proxy s) <$> newline)
<|> crlf
<?> "end of line"
“Common denominator” return type of newline :: m (Token s) and crlf :: m (Tokens s) is certainly Tokens s. No problem, we could use tokensToChunk (Proxy @s) . pure, but it feels like a shame to do that when there are
singleton functions that do the conversion in a list-free fashion, so we
add tokenToChunk to Stream as well.
takeWhileP, takeWhile1P, and takeP
We’ve got 10 methods in Stream type class now. That’s (unfortunately) not
enough. Our aim is to add the following very useful primitives found in
Attoparsec: takeWhile, takeWhile1, and take. They all should return
chunks of input without repacking just like tokens does.
Let’s start with takeWhile and write its signature:
takeWhile :: MonadParsec e s m => (Token s -> Bool) -> m (Tokens s)
Looks about right? With Attoparsec it’s OK to go with this one, but there are subtle details related to quality of parse errors that we cannot neglect in Megaparsec, so the signature will be a bit different.
The problem here is that we know nothing about these Token s things for
which the predicate returns True. Without that information parse errors
will suck. You may be thinking now that adding (<?>) could save the
situation:
space = takeWhile isSpace <?> "white space"
The idiom is valid and has its uses, but it’s not quite the same as:
space = many spaceChar
where
spaceChar = satisfy isSpace <?> "white space"
To understand why, we need to remember that when we match a row of tokens and then fail right after that we should not forget that there could be more of those tokens before the position where we failed at, to illustrate:
λ> parseTest (many spaceChar <* eof) " a"
1:3:
unexpected 'a'
expecting end of input or white space
Megaparsec keeps track of those “possible” matches using something called
hints. (Parsec passes around dummy parse errors from which only “expected”
component is used with the same result.) They are created when something
fails without consuming input in context of a bigger combinator (typically
alternatives with (<|>)) that itself succeeds and are kept until more
input is consumed, then they are discarded by Megaparsec’s machinery:
λ> parseTest (many spaceChar <* many (char 'b') <* eof) " a"
1:3:
unexpected 'a'
expecting 'b', end of input, or white space
λ> parseTest (many spaceChar <* many (char 'b') <* eof) " ba"
1:3:
unexpected 'a'
expecting 'b' or end of input
Furthermore, this is different from labeling the whole thing (I don’t bother to convert the chars to actual number here):
λ> parseTest ((some digitChar <?> "integer") <* eof) "123a"
1:4:
unexpected 'a'
expecting end of input or the rest of integer
This “the rest of integer” phrase is different from just “digit”, so it’s a different thing.
We want to label those individual tokens matched by takeWhile even though
our parsing code never really gets to manipulate them “normally”. So a
better signature is probably something like this:
-- | Parse /zero/ or more tokens for which the supplied predicate holds.
-- Try to use this as much as possible because for many streams the
-- combinator is much faster than parsers built with 'many' and
-- 'Text.Megaparsec.Char.satisfy'.
--
-- The following equations should clarify the behavior:
--
-- > takeWhileP (Just "foo") f = many (satisfy f <?> "foo")
-- > takeWhileP Nothing f = many (satisfy f)
--
-- The combinator never fails, although it may parse an empty chunk.
--
-- @since 6.0.0
takeWhileP
:: Maybe String -- ^ Name for a single token in the row
-> (Token s -> Bool) -- ^ Predicate to use to test tokens
-> m (Tokens s) -- ^ A chunk of matching tokens
We can make the normal “hints” machinery deal with the label and it’s still
possible to label the whole thing with (<?>) for a slightly different
result.
Since Megaparsec is typically imported unqualified, the “P” suffix should prevent name collisions with the standard list functions from prelude.
Implementation of takeWhileP:
pTakeWhileP :: forall e s m. Stream s
=> Maybe String
-> (Token s -> Bool)
-> ParsecT e s m (Tokens s)
pTakeWhileP ml f = ParsecT $ \(State input (pos:|z) tp w) cok _ eok _ ->
let pxy = Proxy :: Proxy s
(ts, input') = takeWhile_ f input
!npos = advanceN pxy w pos ts
len = chunkLength pxy ts
hs =
case ml >>= NE.nonEmpty of
Nothing -> mempty
Just l -> (Hints . pure . E.singleton . Label) l
in if chunkEmpty pxy ts
then eok ts (State input' (npos:|z) (tp + len) w) hs
else cok ts (State input' (npos:|z) (tp + len) w) hs
Nothing new, except we need to add takeWhile_ to the Stream type class
because it’s not expressible via what we have so far. Another addition is
chunkEmpty because we want to use the correct continuation (eok when
nothing has been consumed and cok otherwise):
-- | Type class for inputs that can be consumed by the library.
class (Ord (Token s), Ord (Tokens s)) => Stream s where
-- …
-- | Check if a chunk of the stream is empty. The default implementation
-- is in terms of the more general 'chunkLength':
--
-- > chunkEmpty pxy ts = chunkLength pxy ts <= 0
--
-- However for many streams there may be a more efficient implementation.
chunkEmpty :: Proxy s -> Tokens s -> Bool
chunkEmpty pxy ts = chunkLength pxy ts <= 0
-- | Extract chunk of the stream taking tokens while the supplied
-- predicate returns 'True'. Return the chunk and the rest of the stream.
--
-- For many types of streams, the method allows for significant
-- performance improvements, although it is not strictly necessary from
-- conceptual point of view.
takeWhile_ :: (Token s -> Bool) -> s -> (Tokens s, s)
Now Stream is complete. It’s still not hard to make a type an instance of
Stream, for example:
instance Stream String where
type Token String = Char
type Tokens String = String
tokenToChunk Proxy = pure
tokensToChunk Proxy = id
chunkToTokens Proxy = id
chunkLength Proxy = length
chunkEmpty Proxy = null
advance1 Proxy = defaultAdvance1
advanceN Proxy w = foldl' (defaultAdvance1 w)
take1_ [] = Nothing
take1_ (t:ts) = Just (t, ts)
takeN_ n s
| n <= 0 = Just ("", s)
| null s = Nothing
| otherwise = Just (splitAt n s)
takeWhile_ = span
instance Stream T.Text where
type Token T.Text = Char
type Tokens T.Text = T.Text
tokenToChunk Proxy = T.singleton
tokensToChunk Proxy = T.pack
chunkToTokens Proxy = T.unpack
chunkLength Proxy = T.length
chunkEmpty Proxy = T.null
advance1 Proxy = defaultAdvance1
advanceN Proxy w = T.foldl' (defaultAdvance1 w)
take1_ = T.uncons
takeN_ n s
| n <= 0 = Just (T.empty, s)
| T.null s = Nothing
| otherwise = Just (T.splitAt n s)
takeWhile_ = T.span
-- etc.
takeWhile1P requires at least one matching token:
-- | Similar to 'takeWhileP', but fails if it can't parse at least one
-- token. Note that the combinator either succeeds or fails without
-- consuming any input, so 'try' is not necessary with it.
--
-- @since 6.0.0
takeWhile1P
:: Maybe String -- ^ Name for a single token in the row
-> (Token s -> Bool) -- ^ Predicate to use to test tokens
-> m (Tokens s) -- ^ A chunk of matching tokens
And takeP accepts precise number of tokens to consume as an argument:
-- | Extract the specified number of tokens from the input stream and
-- return them packed as a chunk of stream. If there is not enough tokens
-- in the stream, a parse error will be signaled. It's guaranteed that if
-- the parser succeeds, the requested number of tokens will be returned.
--
-- The parser is roughly equivalent to:
--
-- > takeP (Just "foo") n = count n (anyChar <?> "foo")
-- > takeP Nothing n = count n anyChar
--
-- Note that if the combinator fails due to insufficient number of tokens
-- in the input stream, it backtracks automatically. No 'try' is necessary
-- with 'takeP'.
--
-- @since 6.0.0
takeP
:: Maybe String -- ^ Name for a single token in the row
-> Int -- ^ How many tokens to extract
-> m (Tokens s) -- ^ A chunk of matching tokens
We won’t look at the implementations (which also may be not totally obvious) because they do not introduce anything of interest.
When String is a more efficient type than Text
People often claim that Text is more efficient than String and “serious”
code should prefer Text and ByteString, because String is for suckers.
Well, it depends.
To judge capabilities of our new code, we must understand which operations
are efficient with ByteString and Text and which are not, and how to use
the efficient ones to maximum benefit . There is no magic to make things
faster just because we started to parse Text instead of String.
The terrifying truth: if your parser (Megaparsec or Parsec) parses String
and you just switch to Text, chances are the performance will degrade.
Surprised? Here are the facts:
-
Unconsing is the most common operation that is performed on input stream. This is because most of the time we need fine-grained control that forces us to consume and analyze one token at a time.
-
Stringis a list of characters[Char], the characters are already there. No need to allocate aCharevery time andunconsis a very efficient operation for lists. -
Textisdata Text = Text Array Int Int(omitting unboxing pragmas). NoChars here. Every time we uncons we need to do a lot more work and allocate newChar. It’s slower.
And here are the benchmarks (made with current Megaparsec master):
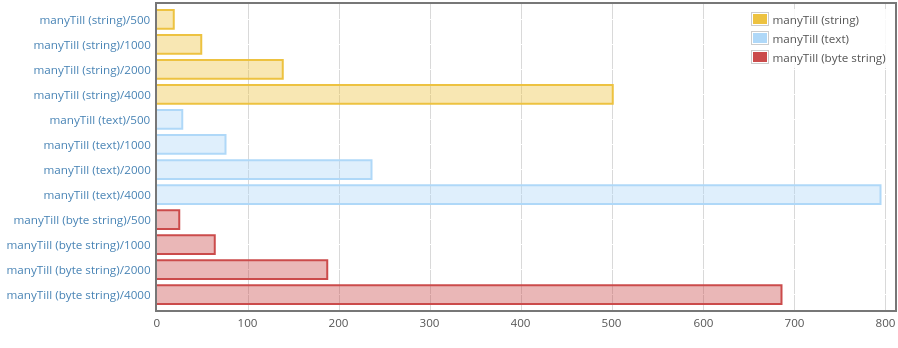
Memory:
| Case | Allocated | Max |
|---|---|---|
| manyTill (string)/500 | 160,312 | 12,024 |
| manyTill (string)/1000 | 320,312 | 24,024 |
| manyTill (string)/2000 | 640,312 | 48,024 |
| manyTill (string)/4000 | 1,280,312 | 96,024 |
| manyTill (text)/500 | 233,832 | 1,192 |
| manyTill (text)/1000 | 466,832 | 2,192 |
| manyTill (text)/2000 | 932,832 | 4,192 |
| manyTill (text)/4000 | 1,864,832 | 8,192 |
| manyTill (byte string)/500 | 164,536 | 104 |
| manyTill (byte string)/1000 | 328,536 | 104 |
| manyTill (byte string)/2000 | 659,136 | 104 |
| manyTill (byte string)/4000 | 1,320,600 | 4,136 |
Note how even though max residency with String is higher, it allocates
less than Text.
So, has Attoparsec gone wrong by not supporting String? How do we save
prestige of Text and ByteString?
There is hope…
It’s true that unconsing is slow, but there are other operations that are
fast. Good news is that we have just wrapped some of them as takeN_ and
takeWhile_.
Efficient operations are typically those that produce Text from Text and
ByteString from ByteString. In other words the primitives that return
Tokens s instead of Token s are fast.
Attoparsec does not make a secret as to where the source of its speed lies (quoting the docs):
Use the
Text-oriented parsers whenever possible, e.g.takeWhile1instead ofmany1 anyChar. There is about a factor of 100 difference in performance between the two kinds of parser.
This is important. Let me show you a picture:
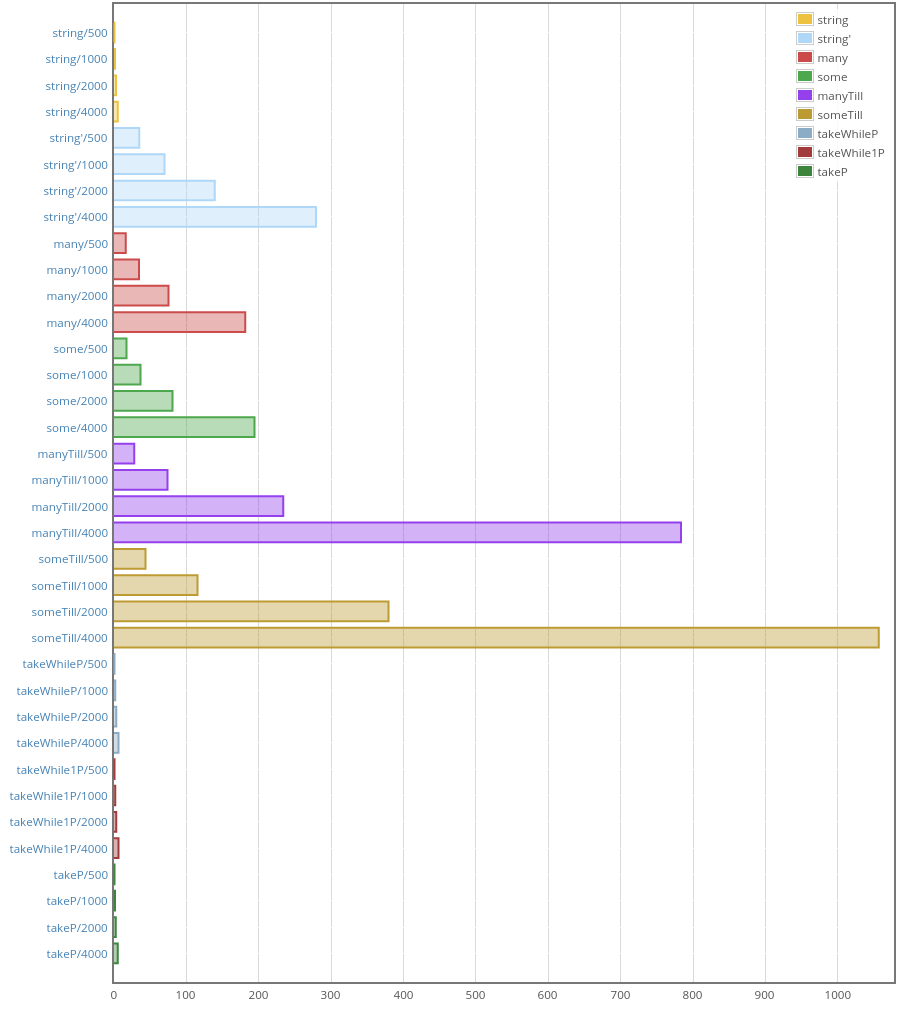
And allocations:
| Case | Allocated | Max |
|---|---|---|
| string/500 | 21,760 | 1,072 |
| string/1000 | 42,744 | 2,072 |
| string/2000 | 84,744 | 4,072 |
| string/4000 | 168,744 | 8,072 |
| many/500 | 201,928 | 1,120 |
| many/1000 | 402,912 | 2,120 |
| many/2000 | 804,912 | 4,120 |
| many/4000 | 1,608,912 | 8,120 |
| some/500 | 221,856 | 1,120 |
| some/1000 | 442,840 | 2,120 |
| some/2000 | 884,840 | 4,120 |
| some/4000 | 1,768,840 | 8,120 |
| manyTill/500 | 246,096 | 1,184 |
| manyTill/1000 | 491,080 | 2,184 |
| manyTill/2000 | 981,080 | 4,184 |
| manyTill/4000 | 1,961,080 | 8,184 |
| someTill/500 | 337,648 | 1,184 |
| someTill/1000 | 674,632 | 2,184 |
| someTill/2000 | 1,348,632 | 4,184 |
| someTill/4000 | 2,696,632 | 8,184 |
| takeWhileP/500 | 21,696 | 1,072 |
| takeWhileP/1000 | 42,680 | 2,072 |
| takeWhileP/2000 | 84,680 | 4,072 |
| takeWhileP/4000 | 168,680 | 8,072 |
| takeWhile1P/500 | 21,696 | 1,072 |
| takeWhile1P/1000 | 42,680 | 2,072 |
| takeWhile1P/2000 | 84,680 | 4,072 |
| takeWhile1P/4000 | 168,680 | 8,072 |
| takeP/500 | 21,728 | 1,072 |
| takeP/1000 | 42,712 | 2,072 |
| takeP/2000 | 84,712 | 4,072 |
| takeP/4000 | 168,712 | 8,072 |
Now that Megaparsec has grown the same sort of “muscle” as Attoparsec, will it make a difference?
Case study: Stache parser
While writing the post, I decided to compare a real-world Megaparsec 5 parser with its upgraded version. The switch wasn’t mechanic, I needed to take advantage of the new combinators to improve the speed.
Here is a PR, I won’t quote the diffs here, but I’ll list results of the switch:
-
I wanted
stringto return strictText, so changing input type to strictTextwas necessary. Not a big deal. -
The new design forces the user to be more consistent with data types he/she is using. Previously I had a mix of
StringandText. Now everything is strictText. Which is a good thing. -
Performance: judging by “comprehensive template” benchmark, the new parser is 43% faster than the old one. You can clone the repo and run the benchmark yourself for more info (the
masterbranch can be used to see performance before the switch).
If you do a mechanical switch to Megaparsec 6, you still may get performance
improvements (provided you don’t switch from String to Text without
knowing what you are doing):
-
If you happen to use
stringa lot, you’ll see an improvement. -
If you use combinators like
spacefromText.Megaparsec.CharandskipLineCommentfromText.Megaparsec.Char.Lexer, you’ll find that they are faster now because they were re-implemented in terms oftakeWhileP.
Still, most of the time manual tuning is necessary to get the most of the new combinators.
Back to Megaparsec vs Attoparsec
Ah yeah, I’ve almost forgotten, we’re “competing” with Attoparsec here.
To update the code to Megaparsec 6 I put takeWhileP and takeWhile1P in a
couple of places, added inline pragmas that I initially forgot for the same
functions as in Attoparsec’s JSON parser. I also followed the good advice
from Attoparsec’s docs:
For very simple character-testing predicates, write them by hand instead of using
inClassornotInClass.
(“By hand” means with satisfy. inClass in called oneOf in Megaparsec
and notInClass—noneOf.)
Then I profiled the parsers and found out that numeric helpers like
decimal can be a nasty bottleneck. I’ll save your time and won’t show the
details here. Right now I’m working on a PR that should heavily optimize all
numeric parsers in Megaparsec (let’s say “no” to read-based
implementations!). At the time of writing it’s not ready yet, but I’ve put
faster implementations of decimal and scientific (borrowed mostly from
Attoparsec source) right into the parsers-bench repo. We’ll have something
as efficient in Megaparsec once I finish with that PR.
I’ve got the following results:
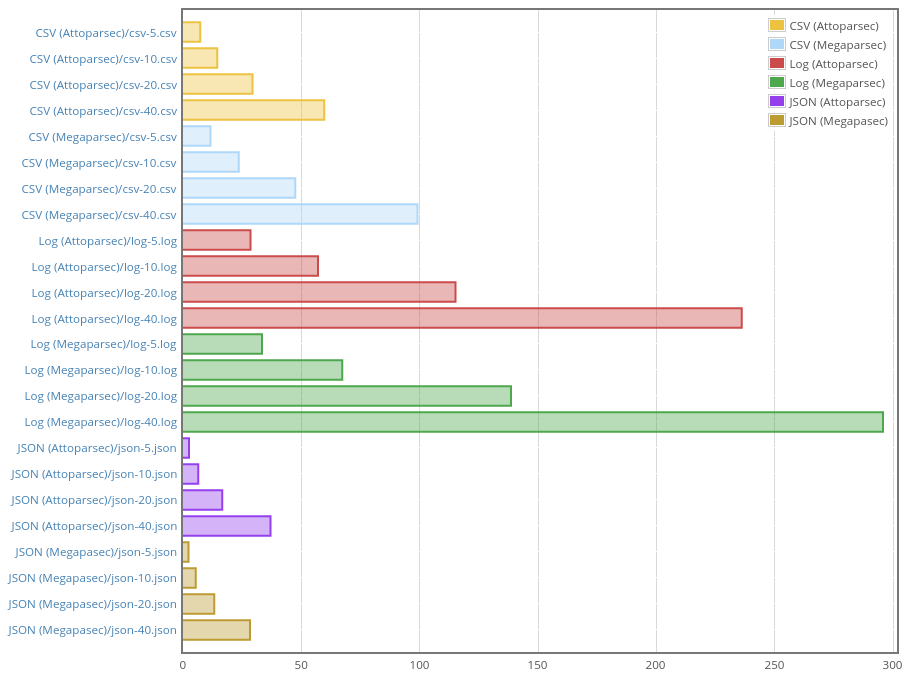
I’m quite embarrassed about the JSON parser. I’m not sure why on the earth it’s even faster than Attoparsec. I tried it by hand and it looks that it produces valid results, i.e. it works. The style is not most natural, but that’s the style Attoparsec uses so it’s only fair to preserve it (we compare libraries, not styles). It may be some sort of mistake on my part, and I hope someone clever will point out what it is as soon as I publish the post. Again, all the code is here: https://github.com/mrkkrp/parsers-bench, so please be my guest.
Conclusion
Megaparsec in version 6 has acquired (or will acquire, upon release) some
appeal that was unique to Attoparsec before. Now we have a collection of
parsers that are 100–150× faster than standard approaches using traditional
combinators like many and token-based parsers. We also avoid repacking
results of token-based parsers as list of tokens (e.g. String) if we
parse things like Text. Megaparsec has to do more bookkeeping to provide
better error messages, but if these fast combinators are put into use like
it’s the case with Attoparsec parsers, the difference with Attoparsec is not
that dramatic is it’s usually thought.
Attoparsec still has its uses though: it’s still faster and supports incremental parsing properly. That said, with Megaparsec 6 released I’ll be more hesitant to use Attoparsec because it’s easier to use one library for everything, especially if it’s more powerful and not much slower.
The version 6 thus will aim to be not just a parser for human-readable texts and source code, but “one size fits all” general solution to parsing in Haskell, including low-level binary parsing.
If you want to play with version 6 (it probably won’t be released for
another month), use something like this stack.yaml file:
resolver: lts-8.20
packages:
- '.'
- location:
git: https://github.com/mrkkrp/megaparsec.git
commit: 9a38f8318e5e06ccf861d0efb6f92031a9db0c49
extra-dep: true
extra-deps:
- parser-combinators-0.1.0
I’m thankful for any feedback you may have. You can open issues on GitHub.